Backend
The FastSearch search endpoint is responsible for embedding user queries, retrieving candidate results from the vector DB, ranking results and logging user queries (see section Feedback loop).
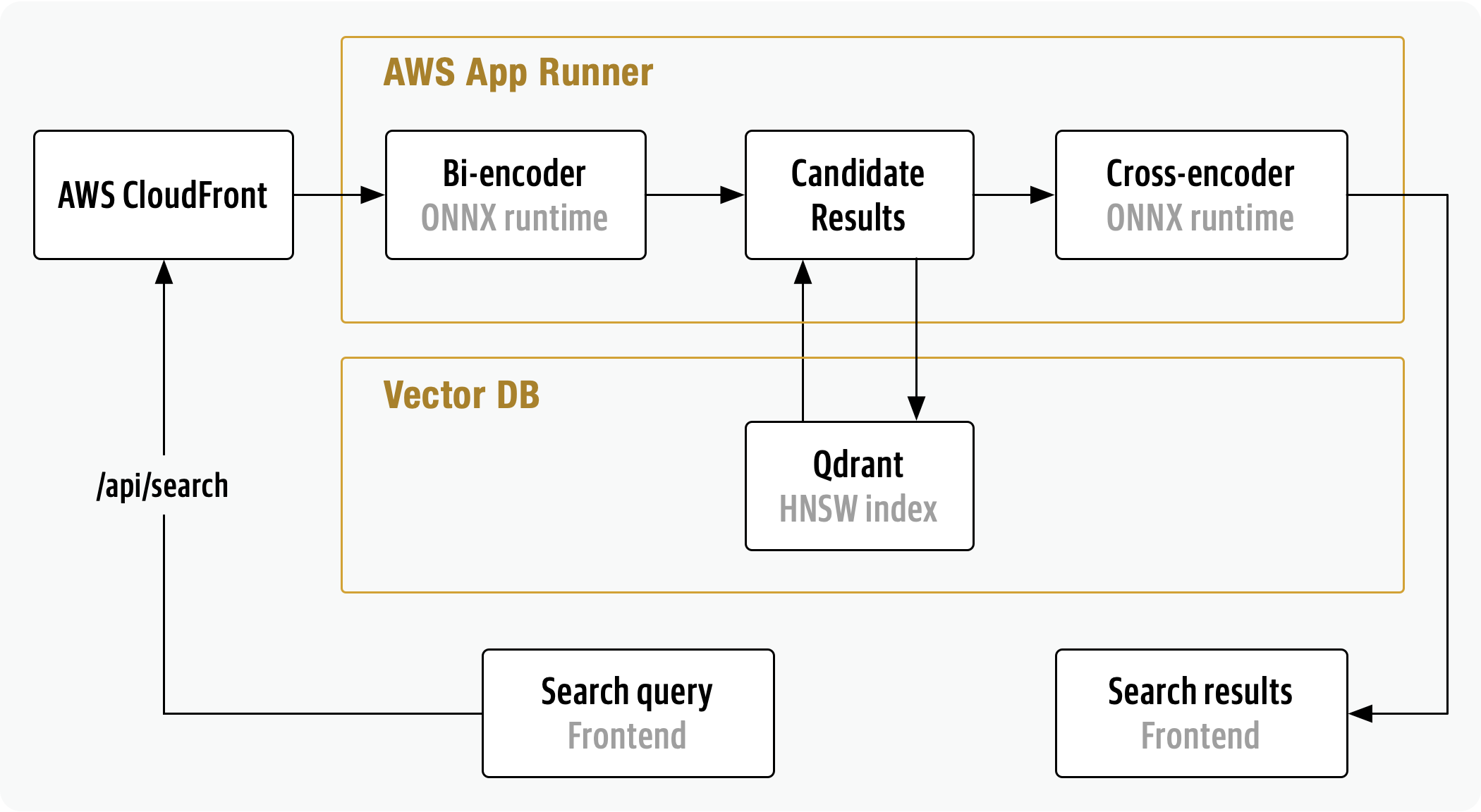
In order to deliver a responsive search experience, FastSearch utilizes:
- AWS App Runner to horizontally scale
- ONNX Runtime to optimize bi-encoder and cross-encoder model inference
- Qdrant vector DB to optimize nearest neighbor search
AWS App Runner
FastSearch is deployed on an AWS App Runner due to its variable traffic pattern and CPU-intensive cross-encoder inference. When deciding where to host FastSearch, a variety of serverless and VM-based AWS services were considered. Top candidates:
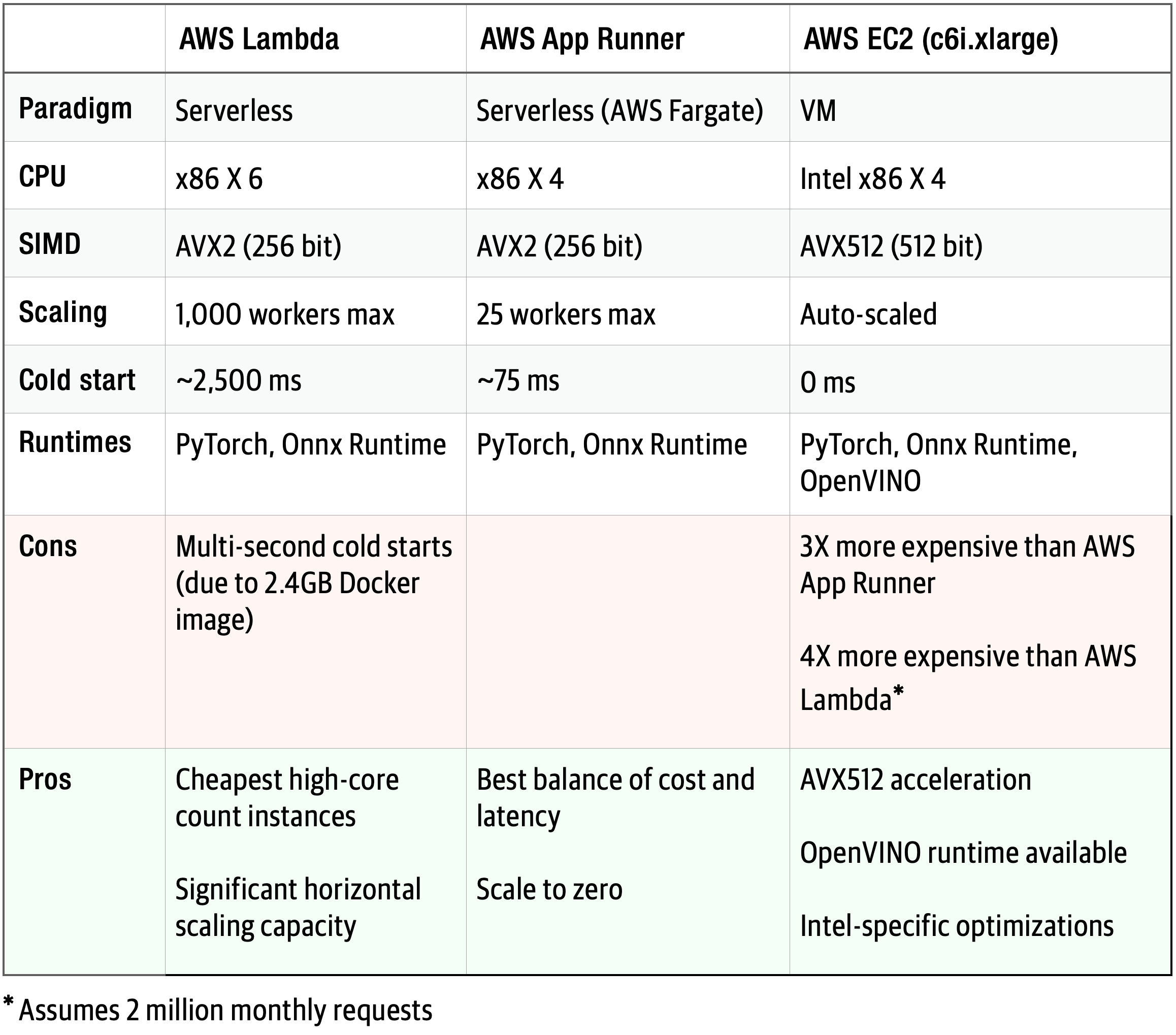
Coming in FastSearch 2.0
As usage increases and the price to performance trade-off equalizes, FastSearch will migrate to an EC2 based load balanced, auto-scaling architecture (see CDK template at GitHub).
Model Inference
FastSearch uses two transformer base models: a lightweight bi-encoder for generating embedding and heavier cross-encoder for ranking candidates. ONNX Runtime is used to optimize inference via computational graph optimization (constant folding, redundant node elimination, attention/embedding fusion…) and INT8 quantization. Together these optimizations lead to improvements of 2.7X in bi-encoder and 1.22X in cross-encoder latency.
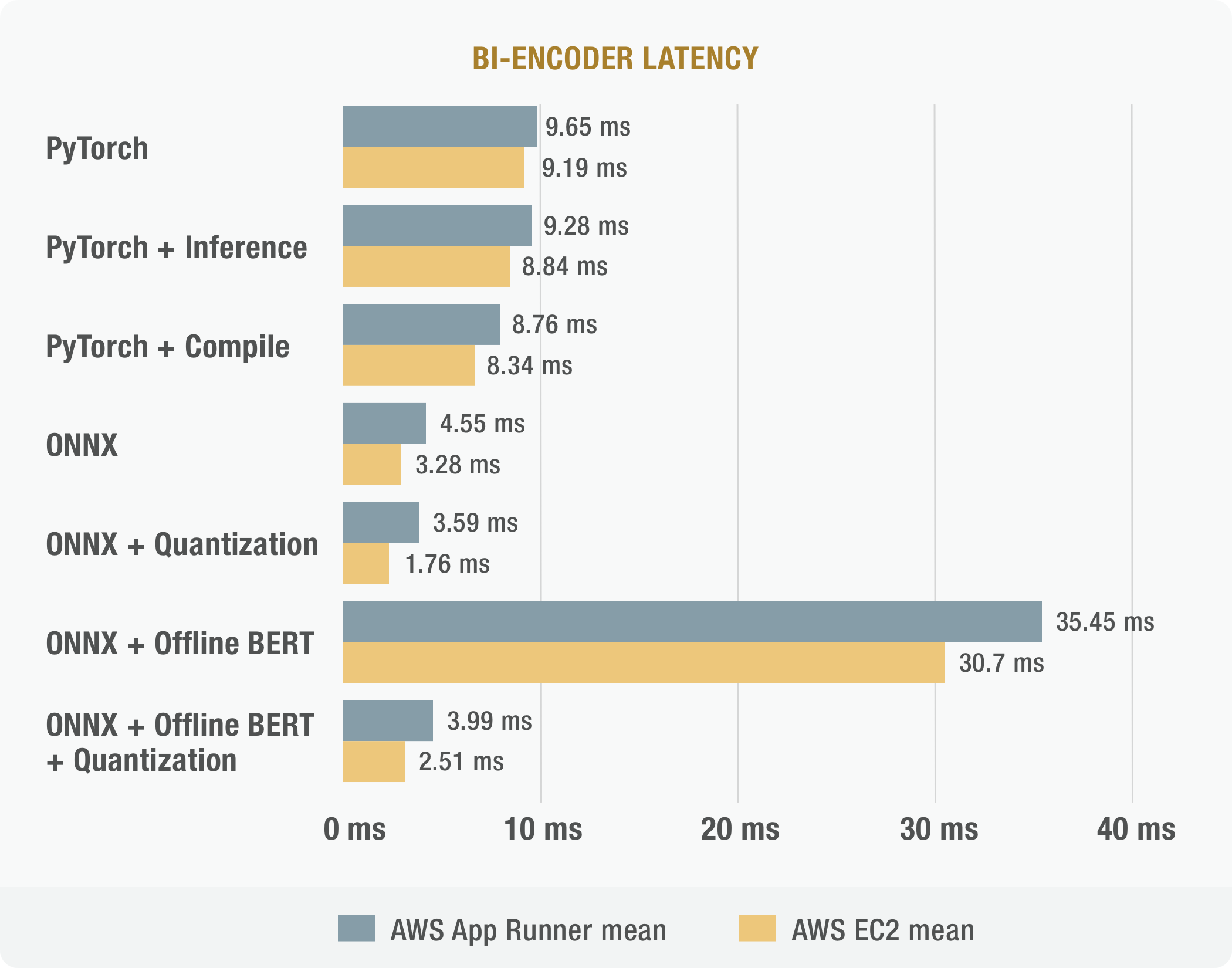
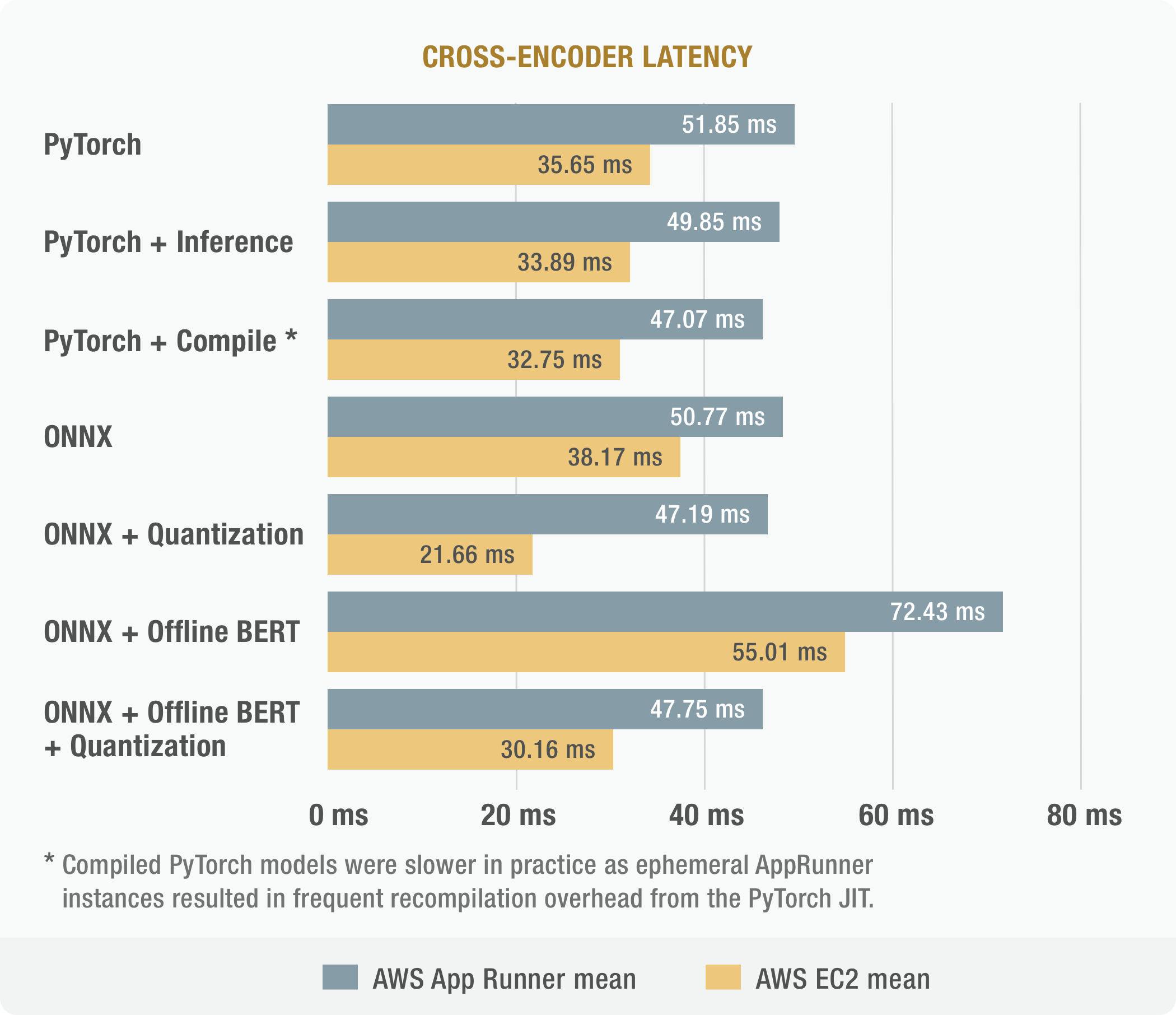
Using the ONNX Runtime also improved cold start time by 18% and reduced the size of the backend Docker container by 726MB / 2.04X by removing PyTorch as a runtime dependency.
Coming in FastSearch 2.0
While the ONNX Runtime has provided a 22% improvement in cross-encoder performance, it is clear that end-to-end inference times are constrained the cross-encoder (pairwise ranking) performance. In order to better utilize the available compute budget, the cross-encoder will be replaced at inference time by a training large bi-encoder (embedding) model.
Vector Database
FastSearch uses an Hierarchical Navigable Small Worlds (HNSW) graph based approximate nearest neighbor (ANN) index to ensure that candidate result retrieval remains efficient as the fast.ai corpus and FastSearch’s index continue to grow.
The HNSW algorithm constructs a hierarchical graph of documents (lecture segments) where edges indicate proximal embeddings and vertices are partitioned into layers by vertex degree. A greedy search algorithm then traverses each layer, comparing node vectors to the query vector, until it finds a local minima, which it follows down to the next lowest layer. This allows the HSNW to quickly search the embedding space without having to compute the distance between the query vector and each document vector, such as in a k-nearest neighbor search.
In order to support continuous, incremental updates and schema/model migrations, FastSearch uses a vector database, rather than directly using an ANN index library such as FAISS, ANNOY or hnswlib. Qdrant is used as the vector database for its simple GRPC client, efficient memory usage, memmap support, built KV storage, and metadata filtering.