Data Pipeline
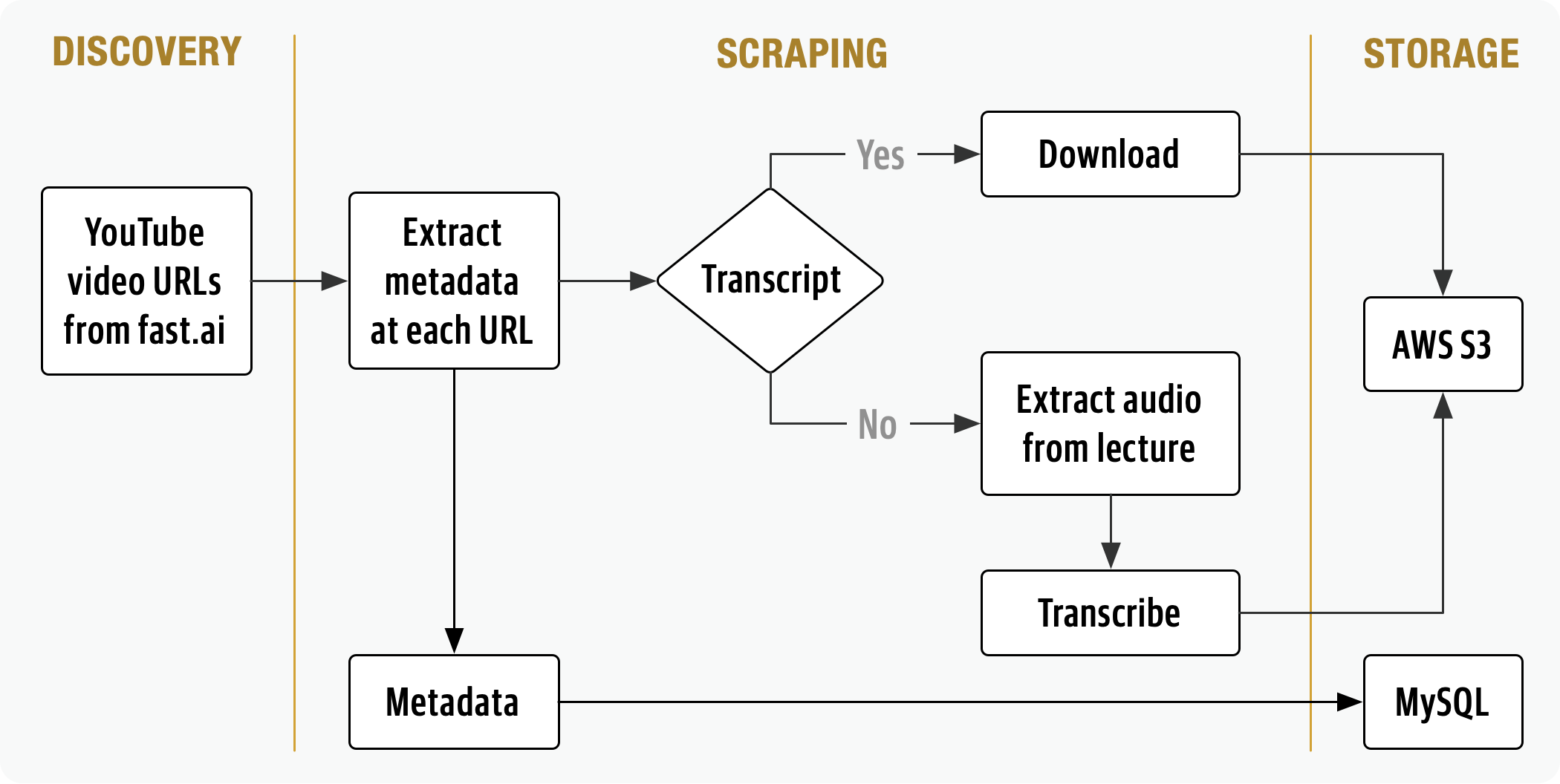
At the core of FastSearch is a data pipeline composed of a scraping pipeline which
- downloads lecture recordings and metadata
- extracts and normalizes lecture metadata into a MySQL database
- generates timestamped lecture transcripts (via GPU accelerated batch inference)
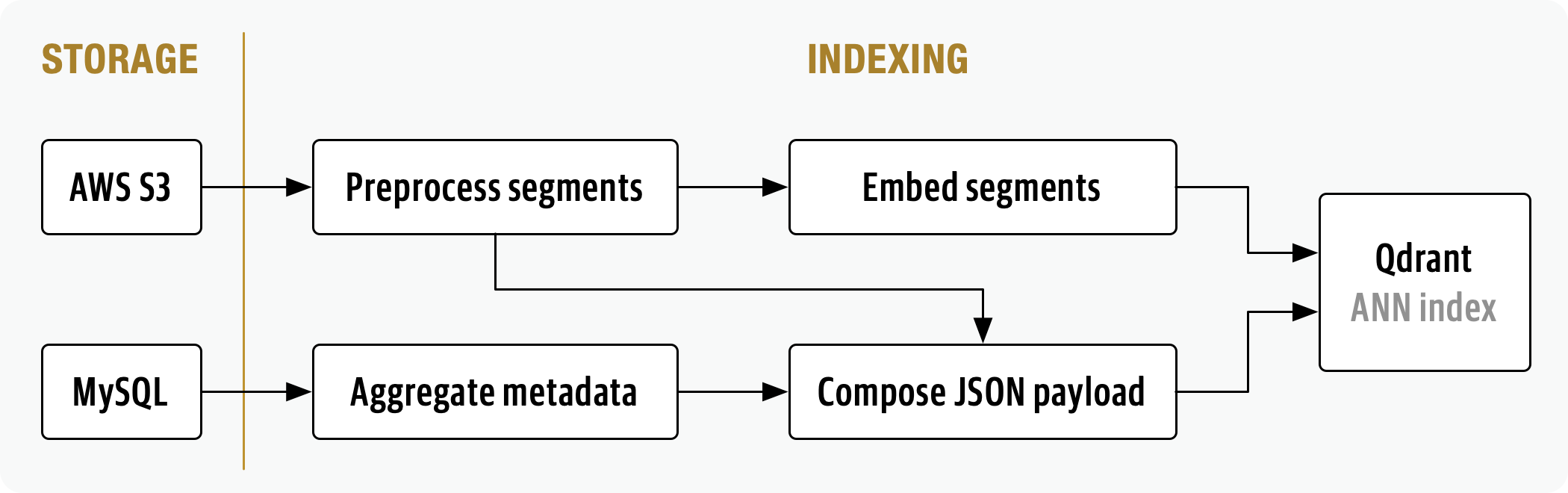
Further, the indexing pipeline:
- creates JSON payloads for the display and ranking of search results
- generates dense embeddings for lecture segments
- incrementally updates the ANN index with embeddings and search payloads
- rebuilds the ANN index when the embedding (bi-encoder) model changes
Transcripts
When available, FastSearch leverages fast.ai student contributed multilingual transcripts. This not only reduces transcription costs, but helps bootstrap next-version efforts to support multilingual search, by using English user feedback to pseudo-label machine translated queries and transcripts. For lectures missing English transcripts, FastSearch falls back on OpenAI Whisper to generate high quality machine transcriptions.
Lecture transcripts are partitioned by language and stored in a versioned AWS S3 bucket, where they are queried using DuckDB (with full text search extension) during model development. This allows for efficient querying of the transcript corpus by metadata or text, without needing a development instance of ElasticSearch or MongoDB.
Coming in FastSearch 2.0
Once enough user feedback is collected, multilingual transcripts will be used to bootstrap support for other languages by this process flow:
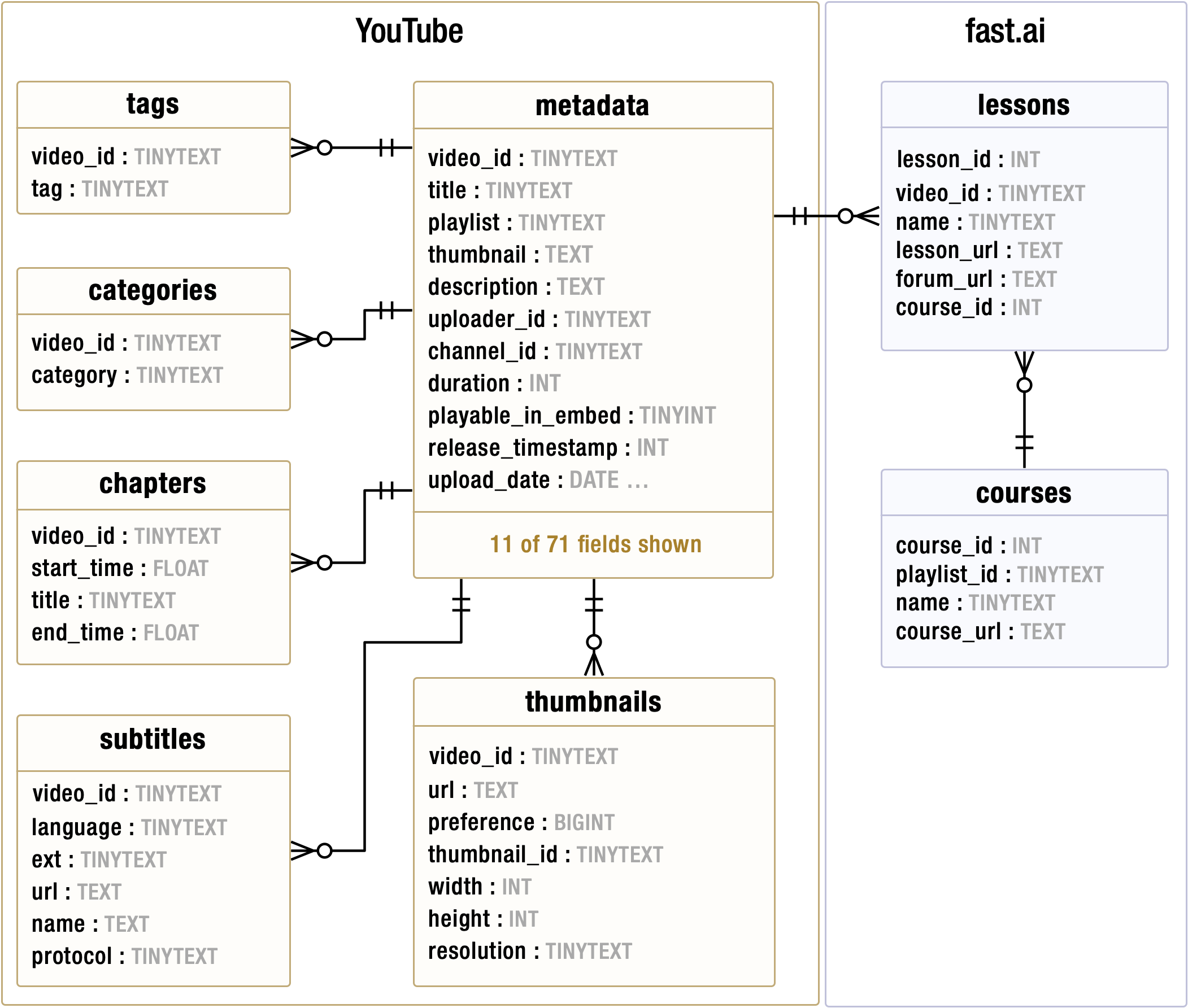
Metadata
Each lecture FastSearch scrapes from YouTube contains 69 metadata fields. Eighteen of the fields are extracted into third norm form and stored in a MySQL database. This ensures data quality for downstream analysis and model development order by enforcing a strict relational data model.
There are three categories of stored metadata: YouTube (id, channel_id, upload date…), video (title, description, duration…) and content (chapters, categories, tags…). Content metadata is used during data labeling for topic-aware sampling for candidate search results. YouTube and video metadata are joined with references to fast.ai course materials to form the JSON search payloads stored in Qdrant vector DB.