Model training
The relevance of search results for a semantic search engine comes down to the quality of the embedding (bi-encoder) and ranking (cross-encoder) models. While semantic search engines can better represent the interactions between words than lexical search engines, they can perform worse on out-of-distribution data. So it was necessary to fine tune the bi-encoder and cross-encoder models to improve their performance on the domain specific fast.ai corpus.
Cross-Architecture Knowledge Distillation
Cross-encoders are more accurate and resilient to out-of-domain data as they perform (cross) self-attention between the query and document tokens. However, they are also slow, as they have to perform pairwise inference across the document corpus for each query. Bi-encoders, on the other hand, create pointwise embeddings and compute faster pairwise distance metrics, such as cosine similarity or dot-product. They are, however, limited to having to represent a document by a single N-dimensional vector.
In order to leverage the power of both models, FastSearch uses a cross-architecture knowledge distillation (https://arxiv.org/abs/2010.02666) to train a bi-encoder on the distribution learned by a more powerful cross-encoder. This limits the number of pairwise comparisons performed at inference time by the cross-encoder to just those documents (lecture segments) retrieved by the more efficient distilled bi-encoder.
Data collection
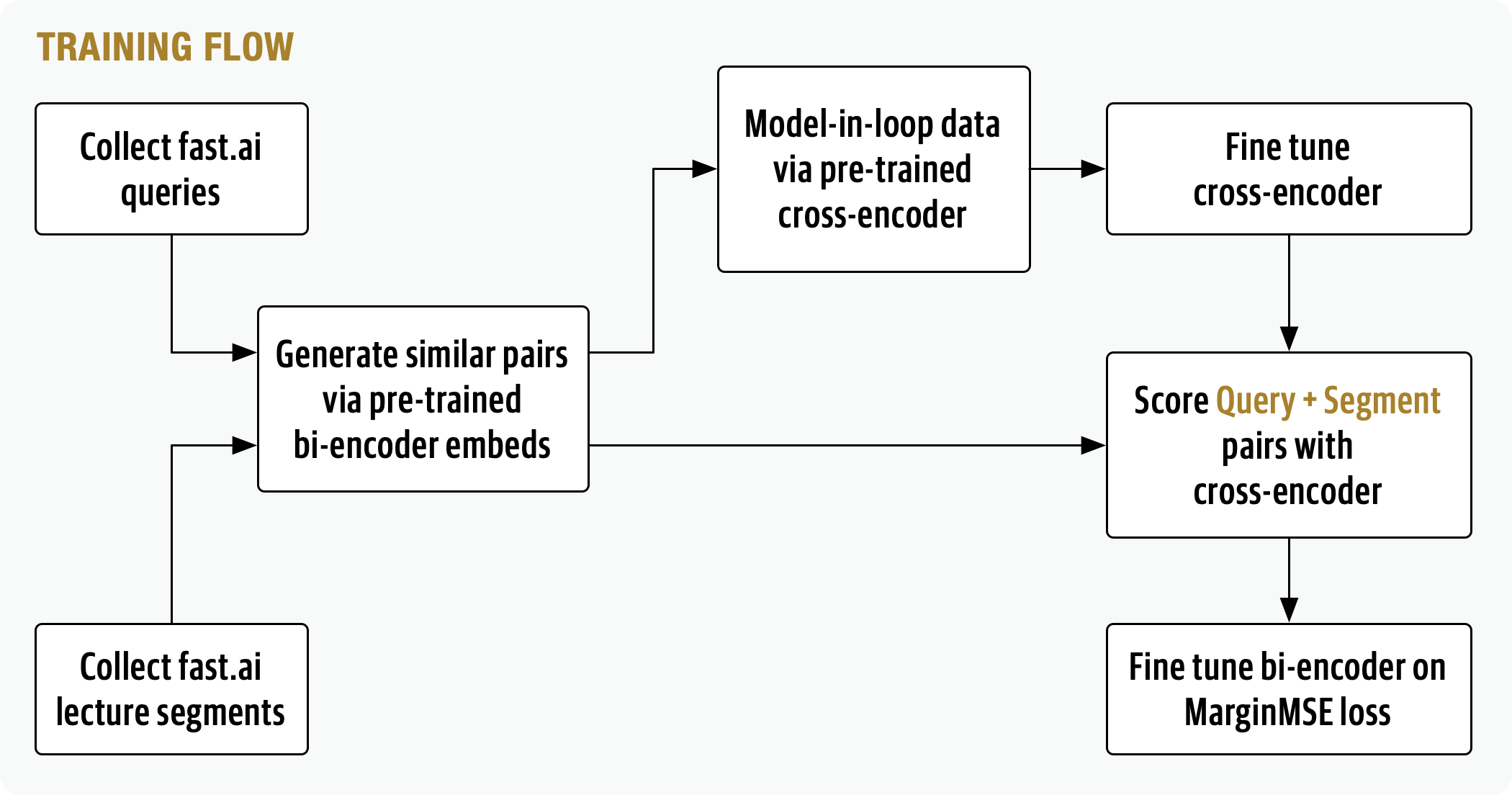
To fine-tune the models I needed a dataset of query+answer pairs, so I collected ~1,000 fast.ai related questions from online sources, such as the fast.ai forums, course pages and third-party blog posts. By sampling the 25 most similar lecture segments to each query, using a pre-trained bi-encoder, I ended up with a ~25,000 pair dataset. This dataset was then hand labeled using a pre-trained cross-encoder to generate candidate labels and Argilla for manual labeling.
Training Models
The cross-encoder trained to predict whether a query+document pair is related uses a semi-supervised approach where:
- A model was first fine-tuned on the subset of labeled query+segment pairs
- The model was used to pseudo label the larger unlabeled dataset
- The model retrained on the pseudo labeled dataset
The bi-encoder is trained on the unlabeled set of query+document pairs using a MarginMSE (https://arxiv.org/abs/2010.02666) loss function, a distillation-based loss function which uses the fine-tune cross-encoder. This loss function eliminates the need to mine hard negatives as the bi-encoder isn’t trained using a classification task, such as is used with the popular MultipleNegativeRanking loss function.
Coming in FastSearch 2.0
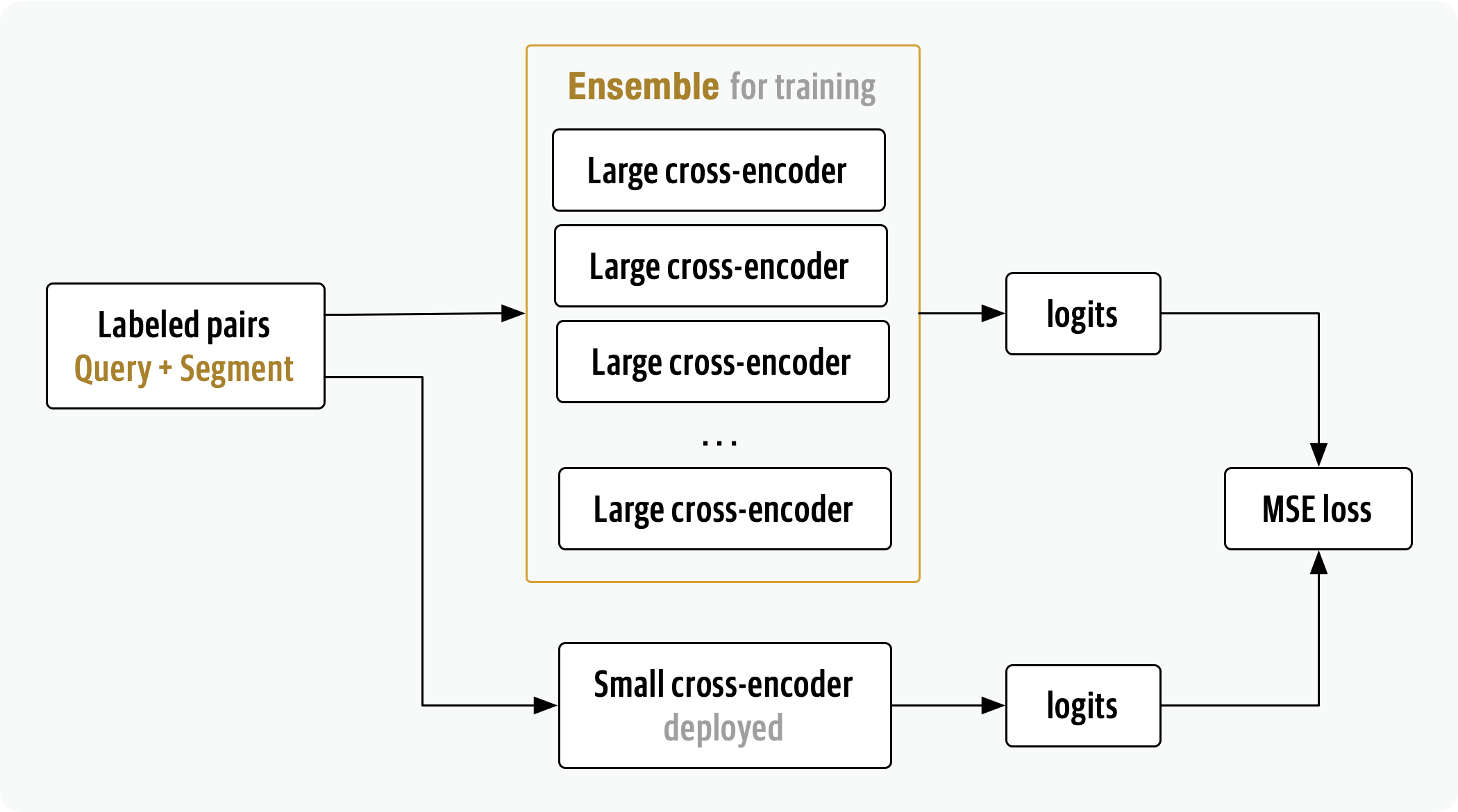
As feedback data and user queries are collected (see section Feedback loop), retrieval and ranking relevancy will be improved by training an ensemble of larger cross-encoders and distilling both a bi-encoder and cross-encoder for inference. This will increase the performance allowing much larger models to better classify query-document pairs and while using smaller model during inference.